What if the AI chatbot you’re chatting with was trained using a secret list of hand-picked websites—without the owners ever knowing?
That’s exactly what happened with Anthropic AI.
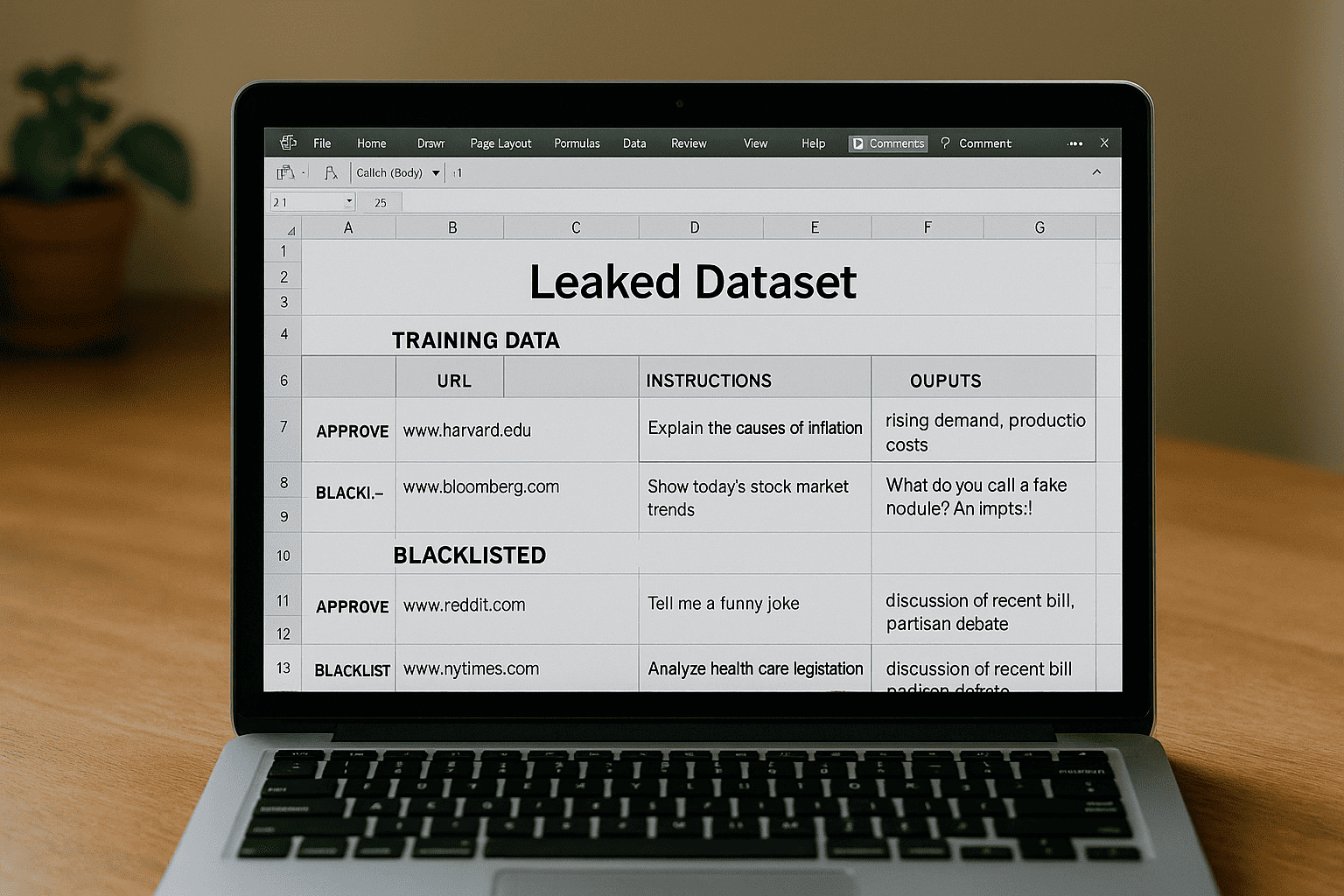
A leaked internal spreadsheet revealed that Surge AI, a contractor hired by Anthropic, created a do-not-use list of over 50 websites… and a whitelist of 120+ “safe” sources like Bloomberg and Harvard. The kicker? Anthropic says they had no idea it even existed.
It raises serious questions about transparency, copyright, and how these billion-dollar AI tools are actually built.
So if you’ve ever wondered what really goes into training these so-called “helpful” AIs, this one’s for you.
Let’s dig in.
Table of Contents
The Spreadsheet Nobody Was Supposed to See
So here’s the scoop.
A leaked spreadsheet recently revealed that gig workers were using a very specific list of websites to train Anthropic AI’s models. Not just any websites. We’re talking hand-picked “whitelisted” sources like Bloomberg and Harvard… and a blacklist that included giants like The New York Times, Reddit, and Stanford.
Even crazier? Anthropic says they had no idea this list existed.
Yup. According to the company, it was created entirely by a third-party vendor—Surge AI, a data-labeling startup they hired to help fine-tune their models.
Let’s unpack what that means—and why this seemingly boring Google Sheet is kind of a big deal.
Who’s Surge AI and What Were They Doing?
Surge AI isn’t just some no-name contractor. They’re a serious player.
They made $1 billion last year and are raising money at a $15 billion valuation. Anthropic, by comparison, is valued at $61.5 billion and is known for its Claude chatbot—basically one of the few real rivals to ChatGPT.
So what was Surge’s job?
They were hired to help train Anthropic’s models to behave more like, well, humans. That means:
- Sounding helpful but not robotic
- Avoiding offensive or weird replies
- Citing real, credible information
To pull this off, Surge assigned tasks to thousands of contract workers. These folks were asked to:
- Pull articles and PDFs from the web
- Feed them into the AI for summarization
- Compare outputs and give feedback
This is part of a process called RLHF—short for Reinforcement Learning from Human Feedback. Basically, humans help the AI get better by rating and guiding its responses.
And here’s where the secret list comes in.
Whitelist vs. Blacklist: The Hidden Gatekeepers
To help gig workers decide what content to use for training, Surge shared a spreadsheet. It wasn’t public… but it also wasn’t locked down. Business Insider found it just sitting open on Google Drive.
What was in it?

- 120+ “approved” websites, including:
- Bloomberg
- Harvard University
- The Mayo Clinic
- Seeking Alpha
- PR Newswire
- 50+ “disallowed” websites, such as:
- The New York Times
- Wall Street Journal
- Harvard Business Review
- Stanford University
You’d think a list like this would be tightly controlled, right?
Apparently not. Anthropic claims it had zero involvement. It was all Surge’s doing.
“We were unaware of its existence until today and cannot validate the contents,” Anthropic said.
Seriously?
Why Some Sites Made the List—And Others Didn’t
So, how did Surge decide which sites were okay and which weren’t?
That’s the weird part: there’s no clear explanation.
But a few clues stand out.
Some blacklisted sites, like The New York Times and Reddit, have publicly pushed back against AI companies using their content without permission. The Times even sued OpenAI. Reddit sued Anthropic earlier this year.
So, the blacklist might just be a way to avoid legal risk.
But that opens another question: Were workers scraping these websites in the first place, and Surge only blocked them after getting caught?
Meanwhile, the “approved” list includes sites that are technically copyrighted—like Mayo Clinic and Morningstar—but have no known deals with Anthropic.
When asked, several of those sites said they’ve never given Anthropic permission to use their content.
So now we’re in murky territory.
The Real Problem: Transparency
Let’s pause for a second.
At its core, this isn’t about one spreadsheet. It’s about trust.
AI companies like Anthropic are building billion-dollar tools that affect everything—from how students learn to how doctors research treatments.
But most of us have no idea how these models are trained. And the companies building them? They often claim they don’t know either.
Sound familiar?
OpenAI and Google have also faced criticism for being cagey about training data. Now Anthropic’s in the hot seat.
If Surge could quietly influence which data goes into Claude… how can anyone be sure of what’s behind the curtain?
“We Take Security Seriously”… Until We Don’t
After Business Insider contacted Surge, they quickly shut down access to the spreadsheet and related documents.

Here’s what they said:
“We take data security seriously… documents are restricted by project and access level where possible.”
Sure. But that clearly didn’t happen here.
This isn’t the first time a data-labeling startup left the vault open, either. Surge’s competitor, Scale AI, reportedly leaked similar internal docs last year.
If these companies are supposed to be the gatekeepers of sensitive AI training material, they’re not doing a great job of guarding the gate.
Okay, But Does This Actually Impact You?
Yes—here’s how.
When you interact with an AI like Claude or ChatGPT, you’re relying on the quality and fairness of the content it was trained on.
If the training process is shaped by hidden lists, biased selections, or accidental leaks, you’re getting a skewed version of “truth.”
Plus, there’s the copyright issue. If AI tools are learning from unauthorized sources, it could lead to lawsuits, broken partnerships, and worse—bad information in the model’s responses.
Think about it. What happens when your AI assistant ignores The Wall Street Journal but favors press releases from PR Newswire?
You’re not getting the full story.
What Anthropic Should (Probably) Do Next
If Anthropic wants to keep its reputation intact, here are a few things it needs to fix:
- Acknowledge the mistake fully
No more “we didn’t know” deflections. - Audit all contractors and vendors
If Surge did this, what else is happening behind the scenes? - Disclose training data policies
What’s in the model? What’s off-limits? Make it clear. - Give users more transparency
Maybe even a way to opt out or see what sources an AI reply is based on.
Will they actually do any of this?
No idea. But they should.
Final Thoughts
Anthropic AI is a powerful tool. Its Claude chatbot is seriously impressive. But power without transparency? That’s a problem.
This spreadsheet leak might seem small, but it shines a light on a much bigger issue: we’re trusting AI companies with enormous influence—and barely asking how the sausage is made.
If you’ve ever used Claude, ChatGPT, or any AI model and thought, “Where is this info coming from?”—you’re not alone.
Now we know, at least partly, the answer.
Read more about Anthropic and its AI’s superpowers.